
Data masking can help ease the pain by pseudonymizing, obfuscating, or otherwise hiding sensitive production data — such as personally identifiable information (PII), payment information, protected health information (PHI), intellectual property, and other confidential data. This process keeps sensitive data protected in production environments (including reporting and analytics) while allowing it to be securely used in nonproduction environments for development and testing.
“Beyond masking confidential data, organizations use masking to anonymize data, removing any identifying fields, such as company name, address, or personal contact information,” said Jerod Johnson, senior technology evangelist at CData Software. “In today’s digital world, protecting customers’ credit card numbers, bank accounts, Social Security numbers, and other personal data is more important than ever before.”
It has always been critical for financial, insurance, and healthcare organizations to use data masking to protect their sensitive data. Today, there is an increased focus on data masking across other industry verticals as well because of ever-evolving privacy and security guidelines, said Vinod Jayadevan, director of insights and data at Sogeti, part of Capgemini.
“With most enterprises embracing or accelerating cloud adoption, the need for robust masking processes and techniques — which can mask data consistently across on-premises systems of records as well as cloud-native data sources — has significantly increased,” Jayadevan said.
Common Types of Data Masking
There are three common types of data masking: static data masking, dynamic data masking, and on-the-fly data masking. According to Jayadevan, static data masking is the most common.
“Static data masking involves persistent masking of data across all applicable data sources,” said Jayadevan. “Masked data will maintain relevant attributes and characteristics — and will fully support production-like operations, testing, and development efforts.”
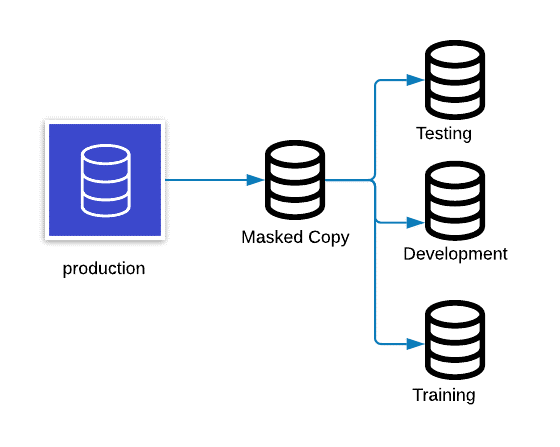
Dynamic data masking, on the other hand, is used to protect production environments and some business-critical regions where persistent data masking may not be a good fit, said Jayadevan.
“In dynamic data masking, the data is not persistently masked at the actual database layer; instead, it is masked in real time to prevent unauthorized users from accessing sensitive information in production or business-critical regions,” said Jayadevan. “The user can view data based on various authentication levels and associated masking rules.”
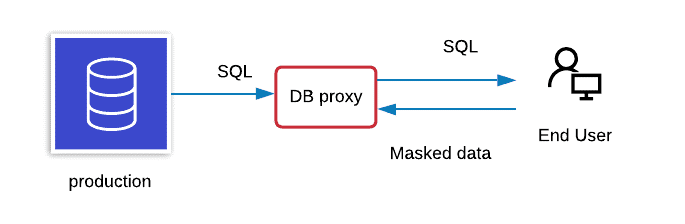
On-the-fly data masking, meanwhile, modifies sensitive data as it’s transferred from a production environment to another environment, such as a development or test environment.
Data-Masking Techniques
There are a variety of data-masking techniques that organizations can use to protect their sensitive data, including:
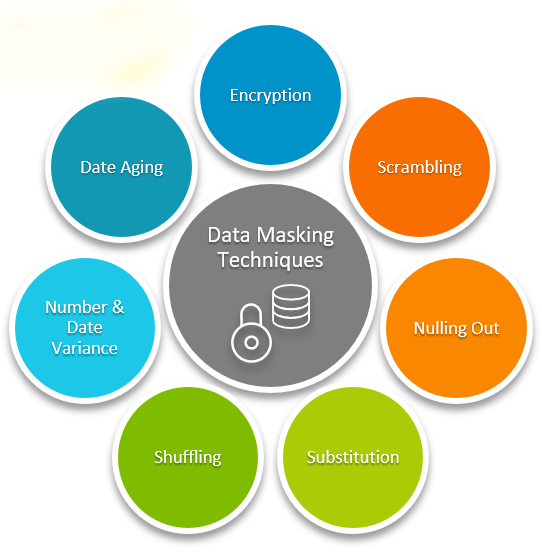
Redaction
Redaction is used to remove some information from the original value in a way that lets the reader know that the value is changed, explained Tim Dalton, group product manager for productivity at Redgate Software.
“For example, think of when a credit card number is replaced by x’s; we know that there are numbers in place there, but we don’t know what those numbers might be — e.g., xxxx xxxx xxxx 1234,” said Dalton. “Redaction is useful when the number of digits is important for developers and others who need to understand how the data is being used.”
Substitution
Data substitution typically masks data by substituting it with another value to alter its meaning — for instance, by changing someone’s first name from “Elizabeth” to “Susan” — while still appearing to be a valid data entry.
“This can take place with a partial value, like only changing the first name or the full data value where the surname is also changed,” said Dalton. “The full obfuscation of the data, often the preferred method, provides the most protection against accidental disclosure of the actual values.”
Alternatively, data substitution can leverage encryption, using randomly generated data as inputs.
“This effectively prevents the possibility of sensitive-data compromise,” said Andy Rogers, senior assessor of Schellman, a global cybersecurity assessor organization, “because the sensitive data does not exist in the application and/or back-end database.”
Nulling Out
This technique masks the data by literally making it so that users cannot view anything in the database by making it blank, Rogers said. Nulling out leverages permissions that are tied to the application user and/or database user, ensuring that users without a need-to-know remain unknowing.
“For protections for nulling out data, the database and application administrators must keep a tight hold on privileges by ensuring that all users have the least amount of privilege that’s necessary for them to perform their duties when dealing with said database and/or application,” said Rogers. “Having a strong account-management and privilege-assignment process is really important here.”
Shuffling
Companies use shuffling when masked data must remain as close to the original data as possible, Rogers said. Shuffled data can “break the relationship” between concrete data values by rearranging data from different rows in the same column.
“Shuffling will remove the ties between the [data values], which further prevents someone from figuring things out,” said Rogers.
The data values themselves may also be shuffled, resulting in transposed characters. (“Andy Rogers” might become “Aydn Rgeosr”.)
At the same time, Rogers explained, companies use shuffling when masked data must be as close to the original data as possible. As such, Rogers cautioned that it is most appropriate for nonsensitive data.
“[Shuffling] is inherently insecure specifically because the algorithm that is used to ‘shuffle’ data can be easily broken,” said Rogers. “The method used for shuffling is a lot like encryption, but the text remains legible; only the relationships and data within the field are mixed up.”
Data-Masking Best Practices
Classify and Catalog Data Before Masking It
The first step of data masking is to identify data by database columns and classify it according to sensitivity, said Dalton.
“Credit card numbers, for example, are very sensitive, whereas first names by themselves are not,” he said. “Once the data is identified and classified, it will make [the] masking process itself far smoother. When a new masked copy of the database is required in the future, the process will already be in place to create it.”
Ensure that Masked Data Truly Represents Original Data
Whatever masking process or tool is used, the result should be that the masked copy of the database looks and feels like the original, said Dalton. The data should have similar distribution characteristics (for instance, be of the same size/length while retaining referential integrity) so that when it’s used in testing, it reflects what will happen in the real world.
Refresh Masked Copies Regularly
Databases can “age” quickly as new data comes in, changes are made, and processing takes place, said Dalton. Accordingly, he suggested that provisioning masked copies of databases should never be a one-off exercise.
“Introduce a process where refreshed copies can be provided regularly,” said Dalton. “Automate as much of the process as possible to ease the burden.”
Encrypt Data that Goes Over the Network
Organizations need to ensure that they’re encrypting data that goes over the network, said Kris Lall, senior product manager at Micro Focus. Lall works on Reflection, a Micro Focus product that enables users to mask data on live host screens, redact data as it’s entered, and prevent access via wireless networks.
“If I go to my office and I log into the network, people can actually see what I’m transmitting over the network, including passwords, if I don’t have encryption turned on,” he said.
Use the Right Data-Masking Techniques
Jayadevan advised that organizations need to weigh both the criticality of the use cases they’re trying to address and the feasibility of implementing particular data-masking techniques in their environments. From there, decision-makers can ensure that they are leveraging the right data-masking techniques and algorithms.
“There is no one-size-fits-all approach to data masking,” said Steve Touw, chief technology officer at Immuta, a cloud data access control platform that provides dynamic data masking. “Understanding what you are protecting and why is critical when balancing access and protection.”
if u need more help please contact us at +91- 93 92 91 89 89 or sales@qaprogrammer.com, www.qaprogrammer.com