
The snowflake is considered because of the following reasons. They are:
· Snowflake is well-known for its easy to use interface. With the system, you can get answers quickly, and you can instantly or on the fly spin up or down high computational clusters of any size for just about any user or amount of work without meddling with other tasks.
· No need to worry about configuration, software upgrades, errors, or ramping up your infrastructure as your databases and user base grow. Snowflake now claims to support modern features like auto-scaling warehouse size, auto-suspends, big data workloads, and data sharing.
· When using Snowflake with a data lake, you can save money by compressing, partitioning, and converting your data to Apache Parquet before loading.
· To achieve high efficiency, you would not have to worry about organizing, leveling, or modifying multi-cluster systems. For example, Snowflake supports automated query optimization.
What is a Snowflake data warehouse?
Snowflake is the first data warehouse as a service cloud-based analytics database. It is compatible with popular cloud platforms like AWS, Azure, and Google. So because the system is completely based on public cloud infrastructure, there is no software or hardware to install, configure, or manage.It’s ideal for data warehousing, data engineering, data lakes, data science, and developing data applications. Its architecture and data sharing abilities, on the other hand, set it apart.
Snowflake Architecture
The Snowflake architecture is intended for cloud computing. Its distinct multi-cluster shared data architecture provides organizations with the required performance, concurrency, and elasticity. From authentication to resource management, optimization, data protection, configuration, and availability, it handles it all. Snowflake has distinct compute, storage, and global service layers.
Snowflake architecture is distinct from other types of architecture, such as Shared disk architectures use various applications to access shared data on a single storage system, whereas Shared nothing architectures store a portion of data on each data warehouse node. Snowflake combines the benefits of both platforms in a one-of-a-kind and innovative design. Snowflake systems queries with hugely parallel processing compute clusters, for each node focusing in one or more fields.
Here we will explore the snowflake architecture in a more detailed way.
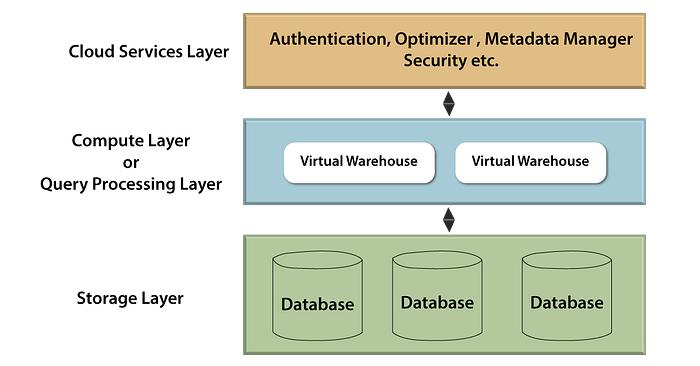
The three layers of snowflake architecture are:
· Cloud service layer
· Database query layer and
· Storage layer
Storage layer:
Snowflake divides the data into numerous micro blocks that are configured and condensed appropriately. It stores data in a columnar format. Data is hosted in the server and operates as a shared-disk model, making data management simple. In the shared-nothing model, this ensures that users do not have to worry about data distribution across multiple nodes.
To extract information for query processing, compute nodes communicate with the storage layer. Because the storage layer is self-contained, we only pay for the average monthly storage usage. Because Snowflake is hosted in the cloud, storage is elastic and charged monthly based on usage per TB.
Cloud service layer:
This layer is where all of the activities that occur across Snowflake, such as authentication, security, metadata management of the loaded data, and query optimizer, take place.
Here is a small example how services are maintained and handled in this layer. They are:
Database query layer:
For query execution, Snowflake employs the “Virtual Warehouse.” Snowflake is the layer that separates the query processing layer from the disk storage. Queries in this layer run on data from the storage layer.
Virtual Warehouses are MPP optimized clusters consisting of multiple nodes with CPU and Memory provided by Snowflake on the cloud. Snowflake allows the creation of multiple Virtual Warehouses for a variety of requirements based on workloads. Each virtual warehouse can only use a single storage layer. A virtual Warehouse, in general, has its own independent compute cluster and does not interact with other virtual Warehouses.
Advantages of the virtual warehouses are:
· Virtual Warehouses can be initiated or halted at any time, and they can also be scaled without affecting running queries.
· They can also be set to auto-suspend or auto-resume, which means that warehouses are suspended after a certain period of inactivity and then resumed when a query is submitted.
· They can also be established to auto-scale with a min and max sequence length, so for example, we can set a minimal level of 1 and an upper limit of 3 so that Snowflake can mandate between 1 and 3 multi-cluster warehouses based on the load.
Snowflake charges for storage and virtual warehouse separately, and these three layers scale independently. The services layer is managed within equipped compute nodes and thus is not charged.The Snowflake architecture has the benefit of allowing us to measure any one layer autonomously of the others.
Now we will learn about the connecting and loading of data into snowflake data warehouses.
Connecting data to a snowflake:
Well, snowflake can be connecting with many other services in a distinct ways namely:
· With the help of web-based User Interface
· Through the ODBC and JDBC drivers
· With the help of command-line clients, native connectors and Third-party connectors such as ETL tools and BI tools.
Loading data into the snowflake:
Now we will explore how to perform loading of data into snowflake. This process is carried with four different options and support namely:
· SnowSQL for bulk loading
· Snowpipe to automate bulk loading of data
· WebUI for limited data
· Third-party tools to bulk load data from external sources.
SnowSQL for bulk loading:
The bulk loading of data is done in two stages: staging files in phase one and loading data in phase two. We’ll concentrate on loading data from CSV files in this section.
· Staging files entails updating data files to a destination where Snowflake can connect them. Load your data from stage files into tables next. Snowflake lets you stage files in internal locations known as stages. Internal stages allow for the secure storage of data files without relying on external locations.
· Loading data — To load data to a snowflake, a virtual warehouse is required. The warehouse extracts data from each file and inserts it into the table as rows.
Snowpipe in order to automate the bulk loading of data:
Snowpipe can be used to bulk load data into Snowflake from files staged in external locations. Snowpipe employs the COPY command, along with additional features that allow you to automate the process. It eliminates the need for a virtual warehouse by using external compute resources to continuously load the data.
Third-party tools to bulk load data from external sources.:
Third-party tools such as ETL/ELT can also be used for bulk data loading. Snowflake supports a growing ecosystem of applications and services for loading data from a variety of external sources.
WebUI for limited data:
The web Interface is the final option for data loading. Select the table you want to load and click the load button to load a limited amount of data into Snowflake. It streamlines loading by incorporating staging and loading data into a single operation, and it deletes staged files automatically after loading.
Snowflake Benefits:
Here we will discuss the key benefits of the snowflake. They are:
· Snowflake has an easy and basic interface that allows you to quickly load and process data. It uses its exceptional multi-cluster architecture to solve problems.
· Data is processed at an optimal rate thereby achieving efficiency and high output.
· In order to run the queries on the bulk datasets they are a wide variety of tools such as tableau and power BI.
· It helps in seamless sharing of data to any client.
· It provides elasticity and flexibility and is also cost effective.
· It achieves scalability and supports multiple data formats for analyzing the data.
Snowflake certifications
Snowflake comes with two types of certifications. They are:
· Snowpro core certification
· Snowpro advanced: Architect
Snowpro core certification:
The SnowPro core certification validates one’s ability to apply core knowledge when enacting and transitioning to Snowflake. A SnowPro core certified professional will recognize Snowflake as a cloud data warehouse and will be able to design and manage scalable and secure Snowflake deliverables to lead business solutions.
· Exam tile: Snowpro core certification
· Cost for the certification is around$175
· Duration of the snowpro core certification is 2 hours
· Passing score percentage of the snowpro core certification exam is 80%.
· Snowpro core certification is available in english and japanese.
Snowpro advanced: Architect
The primary goal of this certificate program is to evaluate an individual’s skills of Snowflake architectural principles. A SnowPro Advanced: The architect will be proficient in the development, design, and deployment of snowflake solutions.
· The cost of the snowpro advanced architect certification exam is around $375.
· The time duration of the certification exam is 90 minutes.
· The number of questions in the snowpro advanced architect certification exam are 60 multiple choice formats.
· This snowpro advanced architect certification is available only in english.
The main topics covered in the above certification exams are snowflake architecture,data cloud provisioning,snowflake storage and security, snowflake account creation and loading, connecting data to snowflake.
if u need more help please contact us at +91- 93 92 91 89 89 or sales@qaprogrammer.com, www.qaprogrammer.com
Share on: